紙の文書をスキャンして PDF にすると、それらの文書とその内容の写真を効果的に作成できます。実際には、これは、結果として得られた PDF をコピーしたり注釈を付けたい場合に、テキストを検索したり選択したりすることはできないことを意味します。その理由は、スキャンされた画像 PDF ファイル内のテキストがコンピューターで認識されないためです。
PDF を検索可能にしたり、Word や Excel などの編集および処理のために別のファイル形式に変換したりするには、まず PDF に対して OCR を実行する必要があります。 OCR は光学式文字認識の略です。このテクノロジーにより、コンピュータは画像内に閉じ込められたテキストを認識して読み取ることができます。
スキャンした PDF をすばやく OCR する方法を説明します。
最初のステップは、信頼できる OCR PDF コンバーターを入手することです。このハウツーガイドでは、以下を使用しています。Able2Extract プロフェッショナル、OCR PDF デスクトップ ソフトウェア。他のほとんどのデスクトップ ツールと同じようにコンピューターにインストールし、起動して画像 PDF ファイルを開きます。
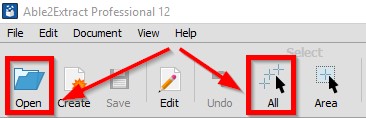
次のステップでは、ドキュメント全体に対して OCR を実行するかどうかを指定します (すべて選択オプション)、または 1 つの領域だけ (エリアを選択)。 PDF 全体を OCR することを選択しました。
選択したら、に進みますファイルメニューを選択し、検索可能な PDF に変換。
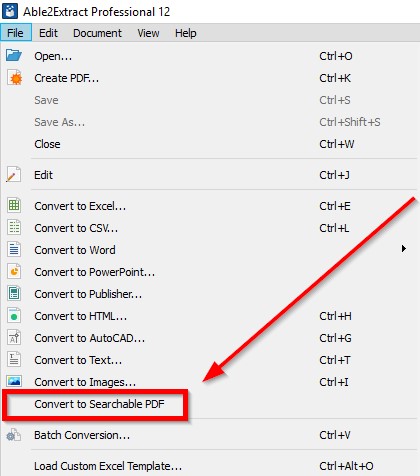
Able2Extract は PDF 上で OCR を迅速に実行し、以下のスクリーン キャプチャに示すように、PDF からテキストを検索して選択できるようになります。
画像 PDF からテキストのロックを解除し、MS Word などの編集可能な形式にエクスポートするには、上で説明したようにコンテンツを選択した後、言葉Able2Extract のメイン ツールバーの [ファイル タイプに変換] の下にあるアイコンをクリックします。ソフトウェアはデフォルトで OCR を実行し、画像ファイルからテキストを抽出します。

OCR 変換の結果、完全に編集可能なテキストを含む書式設定された Word 文書が作成されます。まったく同じ方法で、スキャンした PDF 表を Excel に変換したり、画像 PDF プレゼンテーションを PowerPoint などに変換したりできます。
Able2Extract は、PDF を処理するためのオールインワン PDF ソリューションです。これは、Mac、Windows、および Linux ディストリビューションで利用できるクロスプラットフォーム ソフトウェアです。 PDF を OCR する機能とは別に、ユーザーは次のことが可能になります。
- 印刷可能なすべてのファイル形式から通常の PDF とパスワードで保護された PDF を作成します。
- PDF を Excel にカスタム変換: 変換出力をプレビューするオプションなど、変換前にユーザーの好みに合わせてテーブルを調整します。
- PDF を即座に編集: コンテンツの追加または削除、個人情報や機密情報の編集、PDF の分割と結合など。
- PDFをバッチ変換します。
- 十数種類の注釈を使用して PDF に注釈を付けます。
- PDF フォームに入力して編集すると、データの収集と配布が簡単になります。
- カスタムの通し番号を追加して、PDF 情報を簡単に識別および取得できるようにします。
- ネイティブ PDF とイメージ PDF を MS Office、AutoCAD、HTML などを含む 10 以上のファイル形式に変換します。
これは完全に無料のソフトウェアではありませんが、Investintech.com からダウンロードできる 7 日間の試用版が提供されています。
著者: インベスティンテック