人工知能のサブセットである機械学習は、非常に広大で統計計算指向の分野であり、統計に優れているだけでなく、データの視覚化やデータの前処理にも優れている必要があります。機械学習関連の活動を実行するために、多くの研究者や科学者は、手書きの統計アルゴリズムを使用したり、Excel やさまざまなプログラミング言語を使用して同じことを実行したりするなど、さまざまな方法を使用しています。
ML の観点から人気が高まっているプログラミング言語の 1 つは、間違いなく Python です。これはオブジェクト指向プログラミング言語であり、データ分析や機械学習を非常に簡単に実行できるサードパーティ ライブラリだけでなく、多くの組み込みライブラリも備えています。これは、このタスクに必要なアルゴリズムがこれらのライブラリにすでに組み込まれており、同じものを呼び出すだけで、その作業が数分以内に完了するためです。
Python は ML アクティビティを効率的に実行できるため、市場で非常に人気があり、多くのデータ サイエンティストによって広く使用されています。多くのトップ組織は、R、Scala、Java プログラマーと比較して、Python プログラマーに巨大なパッケージを提供しています。それでは、ML およびデータ分析アクティビティを実行するために一般的に必要となるライブラリがどれなのかを学びましょう。
ML およびデータ分析アクティビティを実行するために通常使用されるライブラリ
パンダ
Pandas は、すべてのデータ サイエンティストとアナリストが必要とする主要なライブラリの 1 つです。このライブラリには、作業したい必要なファイルのインポートなど、さまざまな機能が含まれています。 CSV、Xls、xlsx、tsv など。必要なデータセットをインポートした後、このライブラリで実行できるその他のことは、データセット内の列のデータ型をチェックし、カテゴリからの選択に従って列のデータ型を切り替えることです。数値または浮動小数点数、ブール値に変換します。列の切り替えが完了すると、データセット内の null 値の補間や null 値の削除、null 値の埋め込み、列の転置、さまざまなデータセットの連結、データセットのマージなど、多くのことを行うことができます。強力なライブラリであり、機械学習用の Pyspark よりもはるかに優れていると考えられています。
ナンピー
これは、データ サイエンティストによって使用されるもう 1 つの強力なライブラリです。このライブラリの完全な形式は Numeric Python です。このライブラリは、さまざまな計算関連の問題の解決、データセットの標準分布、ガウス分布への変換、データセットのシャッフル、列のデータ型の変換などに役立ちます。このライブラリは、ランダムな整数、リンスペース、乱数などを使用してダミー データセットを作成するのにも役立ちます。また、このライブラリを使用すると、ユーザーはデータを .npz 形式で保存でき、コード全体を何度も記述するのではなく、その後の計算に使用できます。 。このライブラリを使用して実行できる他の多くの関数があり、適切なドキュメントについては、Numpy の公式 Web サイト (numpy.org) にアクセスしてください。
マットプロットリブ
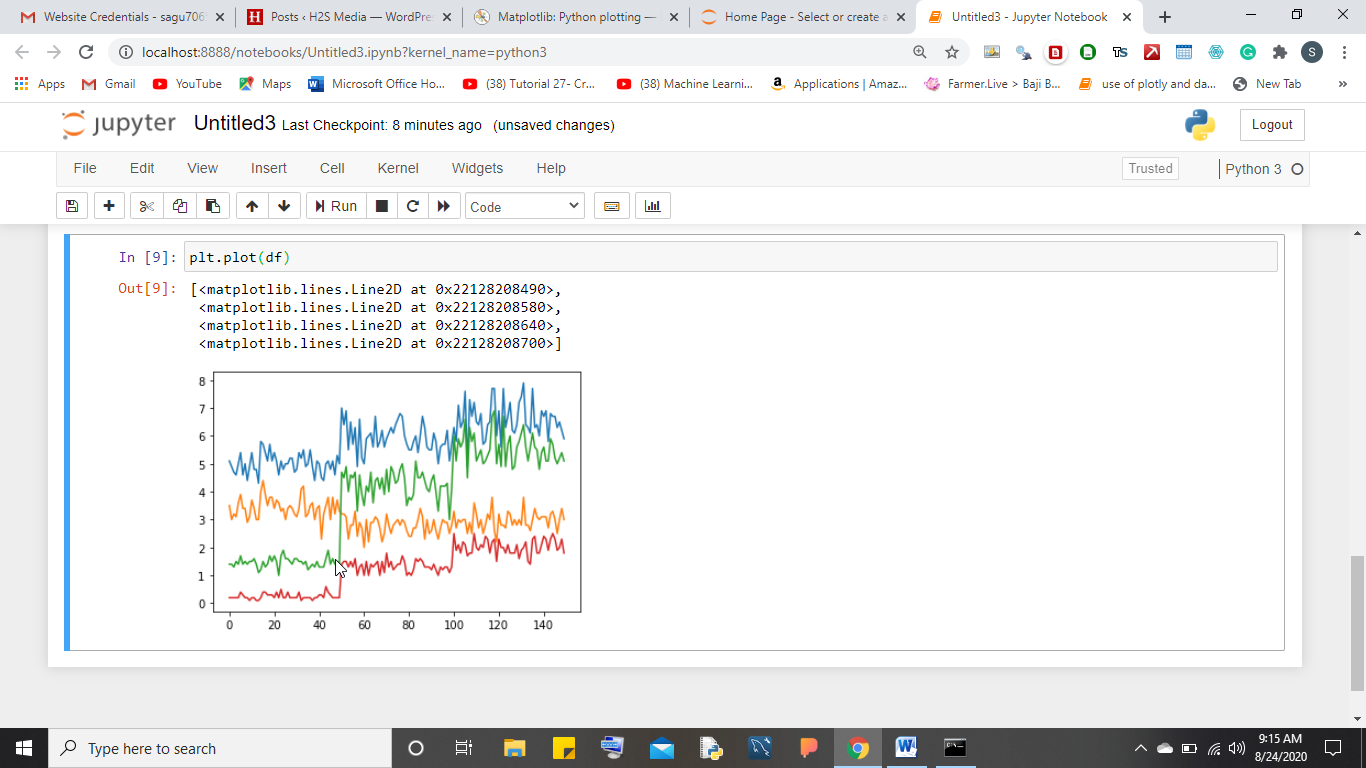
データの傾向分析を生成するためのさまざまなグラフを作成する、データの視覚化に一般的に使用される強力なライブラリです。 Matplotlib ライブラリは、現実世界のケースを解決するだけでなく、さまざまな Kaggle、ハッカソン コンテストを解決するときに最も推奨されるライブラリです。このライブラリの主な利点は、迅速かつ高速であり、グラフが数秒以内に画面上に生成されることです。このライブラリを使用して作成できる最も一般的なグラフには、棒グラフ、ヒストグラム (確率密度)、円グラフ、散布図、折れ線グラフ、正弦グラフ、3D グラフなどがあります。このライブラリを正しく理解するには、次のことを行うことができます。公式 Web サイト matplotlib.org にアクセスしてください。
シーボーン
これは、Matplotlib 上に構築された高レベル API である別のデータ視覚化ライブラリです。これにより、ユーザーは昔ながらのグラフを使用するのではなく、非常に美しい方法でグラフを視覚化できます。また、色相や色などのさまざまな機能を使用して、データの傾向を確認することもできます。このライブラリを使用して構築されたグラフは、非常に高速であるという同じ理由により、データ サイエンティストや研究者によって 2 番目に優先されています。
計画的に
よく、その名前が示すように、高レベル API を備えたデータ視覚化ライブラリ カテゴリにも分類されます。このライブラリは、ユーザーがグラフ上にマウスを移動したり、画面をパンしたり、タイマーを設定してグラフをアニメーション化したり、グラフのセクションを切り取ってさまざまな変動を確認したりすることで、さまざまなポイントを表示できるため、データをより動的に視覚化するのに役立ちます。このライブラリは、脳のセクション、癌、肺炎、その他の疾患を視覚化するために医療分野で使用されています。このライブラリは Plotly 担当者によって正式に作成されており、散布図、折れ線グラフ、サンバースト プロット、棒グラフなど、さまざまな種類のデータ視覚化グラフやグリフを使用できます。詳細については、公式 Web サイトにアクセスし、ドキュメントをお読みください。 Web サイトのリンクは、plotly.com です。
Scikitラーン
Python を使用して機械学習を実行することになると、Scikit Learn が常に頭に浮かびます。これにより、ユーザーは必要な分類アルゴリズムと回帰アルゴリズムをすべてインポートできるようになり、データの標準化、データの正規化、データの学習、テスト、検証への分割、分類レポートの生成、重みの取得など、さまざまな特徴エンジニアリング関連の作業を実行できるようになります。回帰ベースの問題に対するデータの偏り、ダウンサンプリングまたはアップサンプリングなどによるデータのバランス調整などです。これは、Python を使用するすべてのデータ サイエンティストによって最も好まれるライブラリであり、現実世界での最大限の問題の解決に役立ちます。
上記のライブラリはすべて、コマンド プロンプトから pip インストールでき、これらのライブラリの適切なインストールが提供されている pypi.org からダウンロードするか、公式 Web サイトから行うことができます。また、より良いエクスペリエンスを得るには、コンソール内で非常に優れたデータ視覚化を可能にする Jupyter Notebook を使用する必要があります。
結論
Python を介して ML およびデータ分析作業を実行することに懸念がある場合は、これらのライブラリを使用してください。これらのライブラリを使用すると、より速いペースで結果を得ることができ、データを適切に視覚化し、データからあらゆる種類の外れ値を削除することもできます。 。